
Porque “Todo dato tiene su ciencia”, hemos creado una web serie en donde podrás conocer de forma didáctica y con ejemplos prácticos, las diferentes aplicaciones y usos de la ciencia de datos. ¡Te invitamos a verla!
Capítulo 1: Los viajes de José
José es un taxista que, sin saberlo, utiliza los datos para generar información sobre rutas y ahorros de tiempo y dinero, con lo cual toma las decisiones de traslado de sus clientes. Cuando el Decano Mario Ponce sube a su taxi, se da cuenta que con toda la información que tiene, él ha generado conocimiento muy valioso para optimizar su trabajo.
Capítulo 2: Carolina, ¡es hora de salir!
Carolina es una joven trabajadora de la Facultad que cada día sigue una rutina para llegar al trabajo, rutina que ante cualquier imprevisto, retrasa su llegada. Un día su celular le alerta sobre posibles alteraciones en su traslado, por lo que la insta a salir de su casa a la hora indicada. ¿Podrá Carolina llegar a tiempo a su trabajo? La tecnología será su mejor aliada para enfrentar los obstáculos que se le presenten en el camino.
¿Qué es la ciencia de datos ?
La ciencia de datos es una disciplina que mediante la combinación de modelos matemáticos y estadísticos, la programación computacional y las técnicas de visualización de datos, te permitirán obtener el máximo valor de los datos para apoyar los procesos de toma de decisiones.
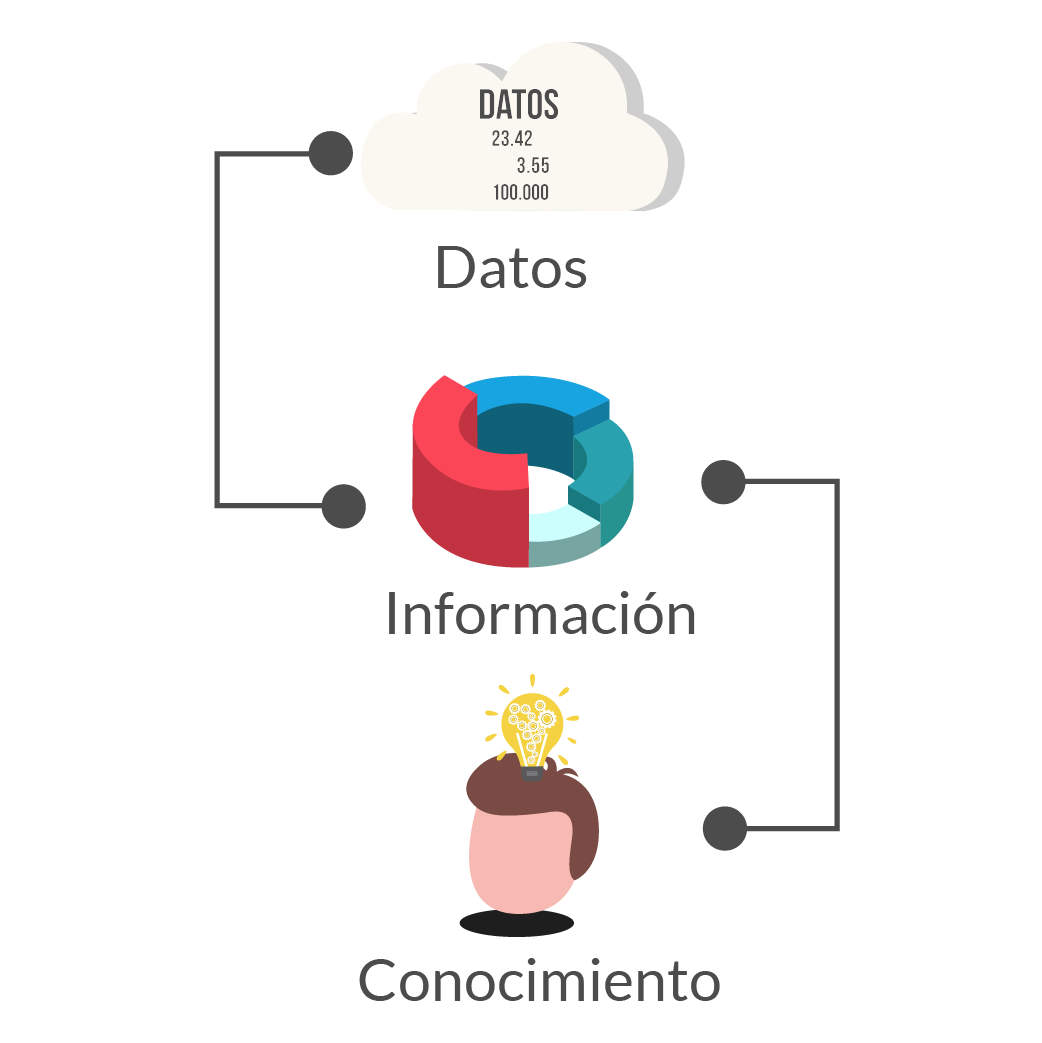
¿Cómo nace la ciencia de datos?
El desarrollo científico y tecnológico nos permite hoy tener acceso a grandes volúmenes de datos, ya que mediante sensores y dispositivos móviles, podemos capturar y procesar minuto a minuto mucha información que antes nunca imaginamos tener. Todo este mar de información, es un fenómeno conocido como big data, el cual requiere de técnicas avanzadas capaces de analizar estos datos en toda su complejidad para así obtener conocimiento relevante.
La ciencia de datos consiste en desarrollar modelos que nos permitan procesar grandes volúmenes de información, y a través de programación computacional, hacer procesos de análisis complejos que superan nuestras capacidades, para transformarlo en lógicas humanas que nos ayuden a tomar decisiones.
¿Cuál es la diferencia entre big data y data science?
Para ilustrar mejor el concepto de big data, podemos resumir sus características y dimensiones en 5 V:
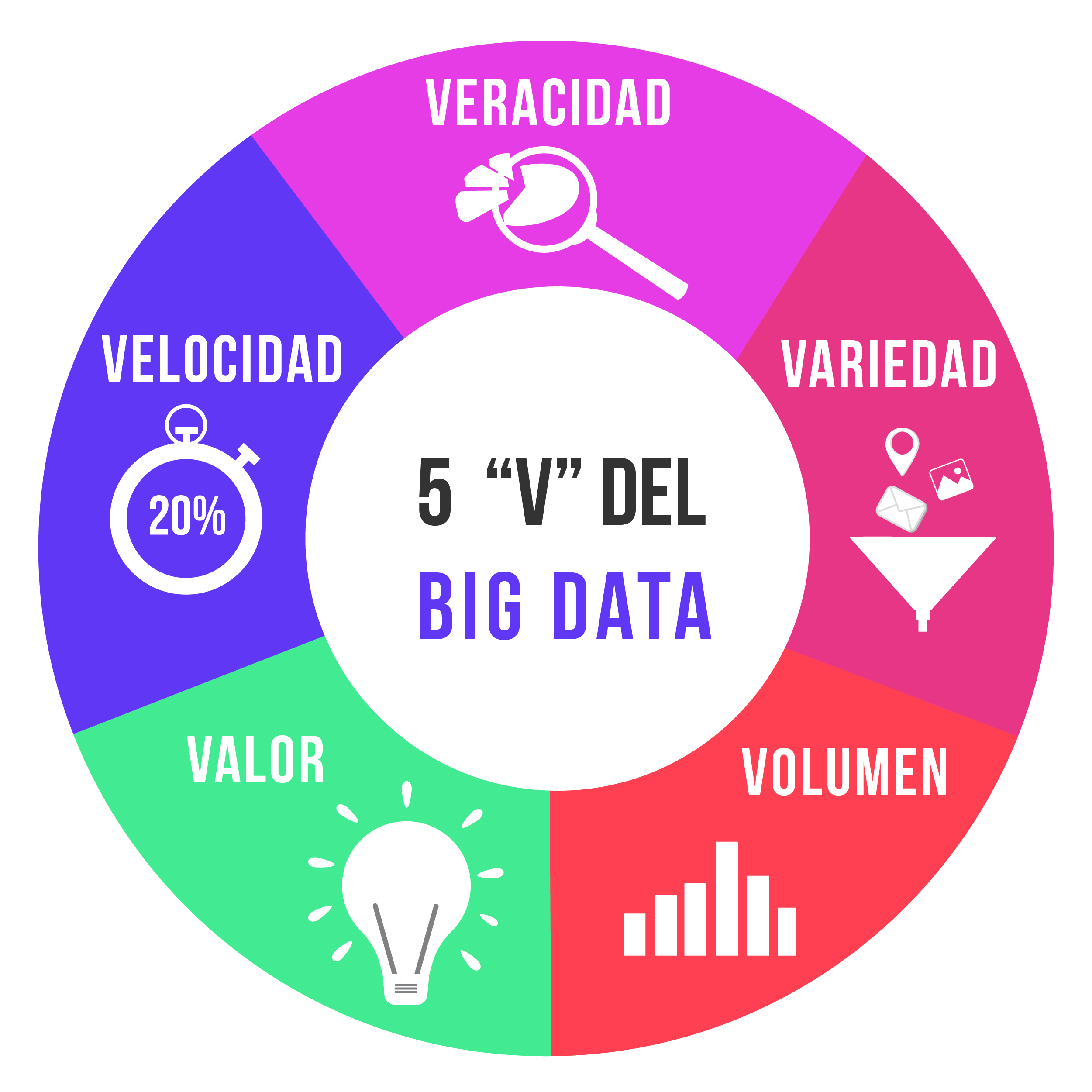
Volumen
La primera característica del big data es que implica grandes volúmenes de información. Actualmente, gracias a los dispositivos tecnológicos, es posible capturar, procesar y analizar miles de datos minuto a minuto, por lo que el primer desafío es desarrollar capacidades técnicas para el procesamiento y análisis de datos masivos.




Variedad
Los datos que se recopilan pueden provenir de diferentes fuentes y además podemos encontrarlos en diferentes formatos: datos estructurados y no estructurados. Dado el origen diverso de los datos, la configuración de procesos de análisis considerando la variedad de éstos, es la segunda característica del big data.
Velocidad
El tercer desafío del big data tiene relación con la velocidad de procesamiento. Al trabajar con datos masivos, se hace necesario contar con capacidades robustas que hagan frente a la volatilidad de los datos, ya que muchos de ellos tienen una corta vida útil y es necesario capturarlos y analizarlos en el momento oportuno para que no pierdan valor.


Veracidad
El siguiente desafío es resguardar la calidad de los datos. Al trabajar con grandes volúmenes de información, se pueden presentar problemas como registros incompletos o erróneos, datos faltantes en determinados campos o información que, proveniente de diferentes fuentes, son discrepantes. La veracidad de los datos es el cuarto desafío en big data.
Data Science, el valor de los datos
La última característica del big data es la V de valor, ¿cómo obtenemos valor de estos grande volúmenes de información? Y esto lo logramos con la ciencia de datos, ya que gracias a las capacidades analíticas, podemos transformar los datos en información y la información en conocimiento.
